Enterprises are racing around to adopt these two technologies simultaneously – cloud computing and AI. The first offers flexibility and scalability to workload at a nominal cost while the other offers unprecedented scope of innovation. These two technologies are truly blurring the lines between large and small enterprises in terms of technology adoption and creating a level playing field. Our article takes a deep dive into the possibilities of these two technologies benefiting businesses combinedly in the form of a promising tech – Cloud Native AI (CNAI).
What is Cloud Native AI?
Cloud native is an approach to build a scalable technology environment with containers, service meshes, microservices, immutable infrastructure, and declarative APIs. The tremendous evolution of AI/ML solutions in recent times warrants an infrastructure that can support their large workloads. The AI models of today that deal with trillions of parameters require unlimited storage, huge computational power, and most importantly the ability to scale these resources as required. Data security is another concern as the data used to train a model might be sensitive. While some large enterprises may turn towards setting up an on-premises infrastructure that’s a lot of capital blocked as an upfront cost and an additional workload of provisioning and decommissioning resources. Cloud Native AI is the approach where these infrastructure gets deployed and scaled as required automatically in a secure cloud environment while the AI engineers can focus on core things related to the model.
The following is an image that represents the cloud native AI architecture schematically.
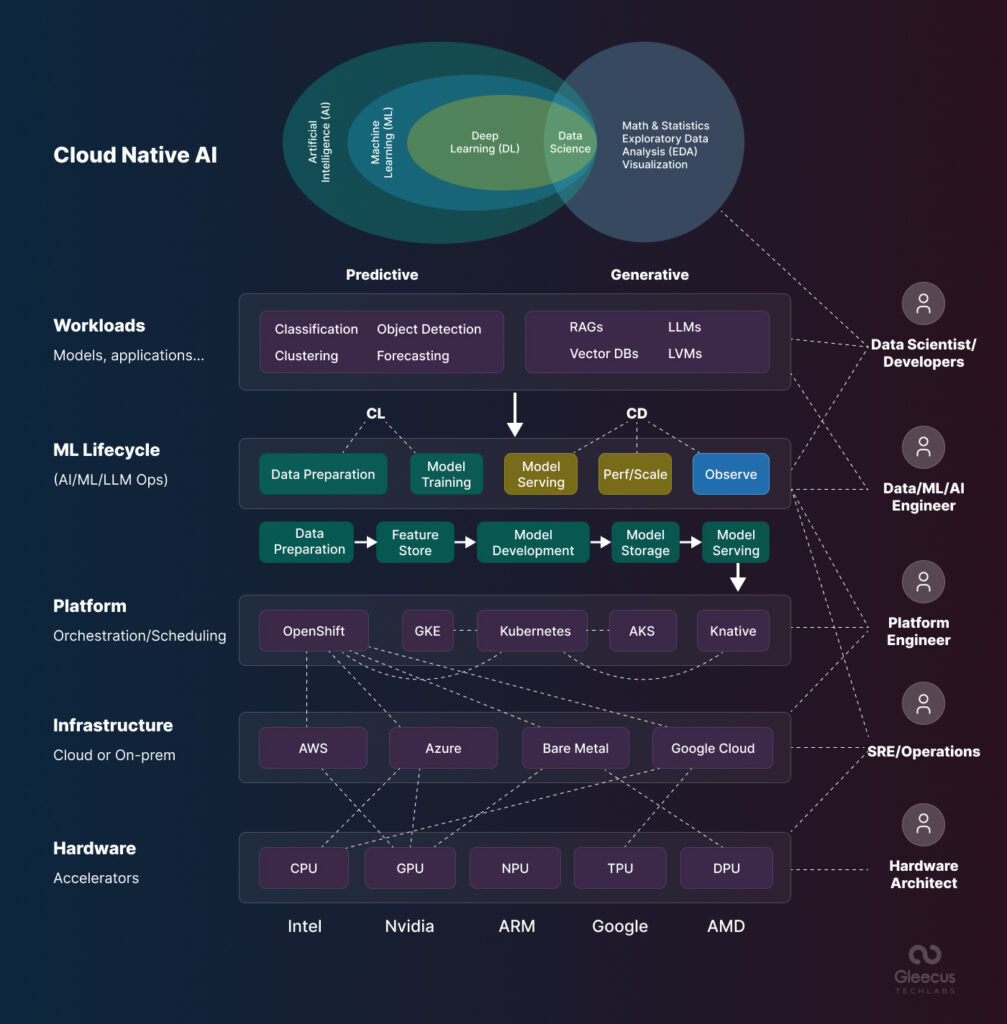
Benefits of Cloud Native AI Infrastructure
Scalability
An important orchestration tool in cloud is Kubernetes that can automatically scale up and down resources based on demand. This is an important cost saving criteria for AI projects where there can be sudden burst in demand for computing power followed by a sharp drop in demand. Scalability ensures that an AI model can seamlessly handle increased data, support a larger user base, and manage more complex queries without performance degradation.
Resilience
Deploying AI systems across different cloud providers following a multi-cloud approach instills resilience. A lot of cloud providers offer Automated machine learning (AutoML) pipelines under their services like Azure ML, Google’s AutoML and Amazon’s SageMaker Autopilot. AutoML pipelines streamline continuous assessment of model’s performance in production and retraining to maintain model quality and resilience. Manages services, such as AWS S3 Cross-Region Replication or Azure’s geo-redundant storage (GRS), that set up redundant data storages and process pipelines across regions should be a part of disaster recovery strategy of AI pipelines.
Flexibility
Different AI models have different conflicting dependencies. Cloud is almost synonymous with microservices based architecture. The containerized architecture of a cloud provides flexibility to update and deploy new models or components without disrupting the entire system. Hybrid and multicloud platforms offer even better flexibility where containerized workloads can be moved around in different environments without disrupting the entire system.
Resource Efficiency
Auto-scaling services in cloud optimizes AI workloads. Serverless computing allows companies to run applications and services without managing servers, which optimizes AI workloads by dynamically allocating resources based on demand. The concept of Edge to cloud computing allows complex processing happening on the device while allowing cloud as a platform of connectivity enabling faster delivery of outputs.
Challenges of Cloud Native AI
Although a flexible, scalable platform makes a cloud native AI a high-performing model it is not devoid of its own challenges. The challenges vary depending upon AI’s scale and latency needs. We outline some of the common challenges of cloud native AI in the following section.
Data Preparation
There is an escalating need for high-quality data for AI/ML solutions underlying the need of gathering data from multiple disparate locations in different formats. ML workloads don’t have an industry standard interface while SQL plays a crucial role in providing users with a familiar uniform experience. Consequently, data scientists develop their ML Python scripts with small datasets locally. Distributed systems engineers then rewrite these scripts for distributed execution. If the distributed ML workloads function unexpectedly; data scientists might need to debug the issues using their local Python scripts. This process is inefficient and often ineffective and exists despite the availability of better observability tools and the reproducibility afforded by container technology.
Model Training
Using cloud native technology for AI can be complex regarding GPU virtualization and dynamic allocation. Technologies, such as vGPUs, MIG, MPS, and Dynamic Resource Allocation (DRA), enable multiple users to fractionalize GPU (share a single GPU) while providing isolation and sharing between containers in a pod.
Coordinating the scaling of different microservices, each designed to encapsulate specific AI functionalities, requires complex orchestration to guarantee smooth communication and synchronization. Additionally, the diversity of AI models and frameworks adds complexity to standardization, making it difficult to develop universal scaling solutions that can be applied across multiple applications.
Model Serving
Cloud-native architecture relies on microservices, which can present challenges for AI when treating each stage of the ML pipeline as a separate microservice. The presence of numerous components can complicate the maintenance and synchronization of outputs and transitions between stages. Even if users intend to experiment with these solutions on their laptops, they may still have to set up multiple Pods. This complexity can hinder the infrastructure’s ability to adapt flexibly to diverse ML workloads.
Another important factor is response latency, which varies greatly depending on the use case. For example, the latency required for detecting objects on the road in autonomous driving is much lower than what is acceptable for tasks like generating an image or composing a poem. In high-load situations, additional serving instances may need to be deployed for low-latency applications. These instances could utilize CPUs, GPUs, or other computing resources if the required latency can be achieved. The support for such adaptive scheduling of resources in Kubernetes is still in development.
Right-sizing Resource Provisioning
AI/ML workloads, particularly those involving large language models (LLMs) with billions or trillions of parameters, require significant resources. As previously mentioned, accelerators like GPUs are costly and in limited supply, making it crucial to allocate the right amount of resources to optimize usage and manage costs. We must be able to not only time-slice GPUs but also partition them into fractional sections and allocate them wisely according to the demands of various workloads. Alongside these back-end efforts, there is also a need for front-end support to request GPU sub-units and configure them during the launch of workloads.
Best Practices for Leveraging Cloud Native Technologies for AI
Embrace Flexibility
With the diverse options available in AI, it’s essential to utilize established tools and techniques that integrate well with cloud-native technologies. Utilizing REST interfaces to access cloud resources can streamline workflows and ensure compatibility as new offerings emerge.
Focus on Sustainability
To enhance ecological sustainability, prioritize projects and methodologies that clarify the environmental impact of AI workloads. Implement strategies for optimizing workload scheduling, autoscaling, and tuning. Advocate for standardized environmental impact assessments and promote the development of energy-efficient AI models.
Ensure Custom Platform Dependencies
Confirm that your cloud-native environment includes the necessary GPU drivers and supports GPU acceleration for AI workloads. This is vital since many AI applications rely on specific frameworks and library versions that may not be compatible with standard container images.
Utilize Reference Implementations
Consider adopting a cloud-native, OpenTofu-based reference implementation that combines various open-source tools to create a user-friendly experience for AI/ML development. This approach can help teams quickly scale their machine learning efforts by leveraging tools like JupyterLab, Kubeflow, PyTorch, and others.

