For a generic user, the concept of AI is straightforward: it takes in data, performs some intelligent operations, and delivers a valuable output. But this is not so simple, data science plays a crucial role in the AI architecture. It builds the analytical framework and provides the necessary tools to process, analyze, and identify relevant patterns in data. This in turn guides the AI solution to deliver its expected results.
Without having knowledge of what happens with the data inside the AI-engine problems like bias or “black box problem” are more likely to occur. You can’t build high quality AI /ML models without having awareness and control over data science technology and practices- In other words, an AI model with poor data science and engineering architecture will reflect the age-old saying ‘Garbage In, Garbage Out’. In this article, we will give a brief outline of the AI workflow with data science serving as the underlying core of an AI engine.
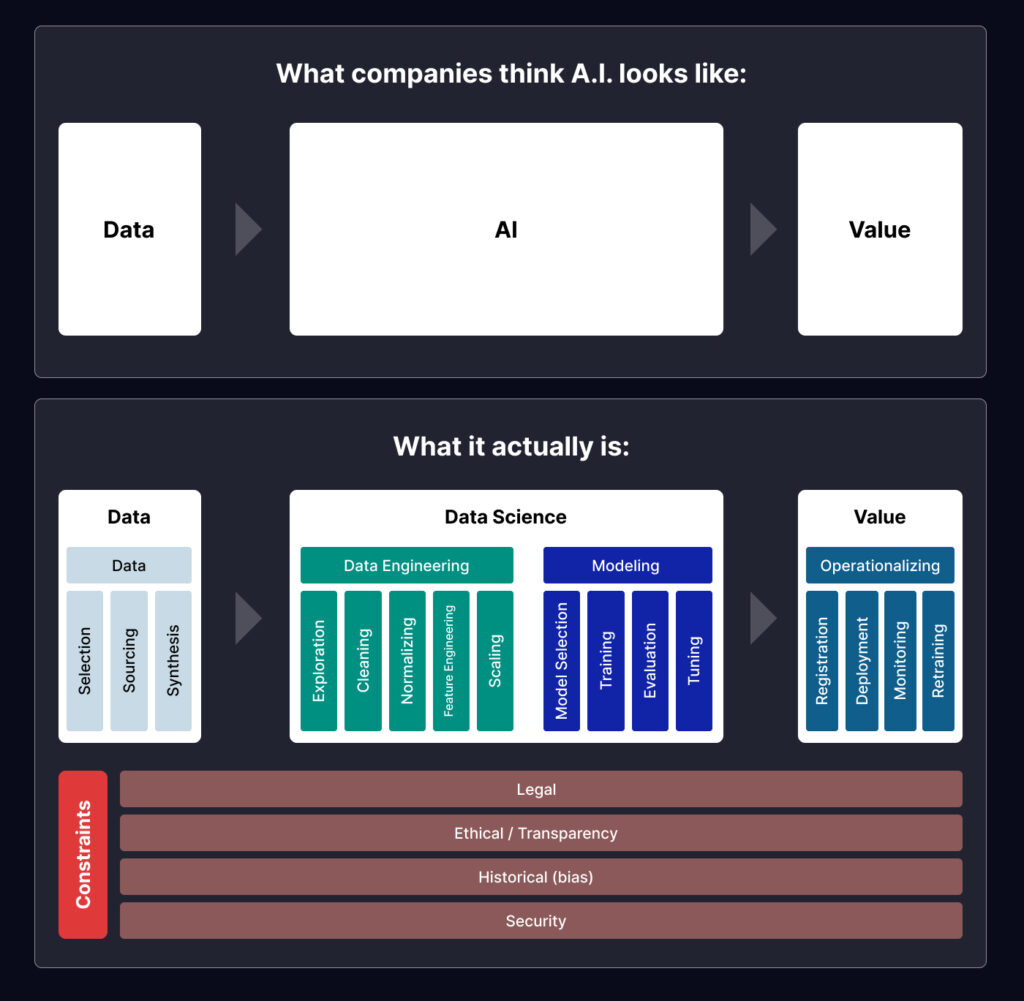
Starting with Data: The Raw Material for AI
Large datasets serve as the feed to AI systems that iteratively learn from patterns and features within the data. To ensure your data is useful as a feed pay attention to the following factors:
Data Selection
Consider your model’s data requirements. This may be structured data arranged as flat files or unstructured data as text, images, video, and audio clips. Prioritize high quality data and ensure they are relevant, accurate, and representative of the problem you are attempting to solve.
Data Sourcing
High data quality is crucial in training AI models. For custom Enterprise AI models, niche data might not be available in the public domain. You need to extract and label your enterprise data. Consider crowdsourcing data from a large group of people via simple tasks or questionnaires as a cost-effective option. If your budget is low look for free datasets available in online repositories. You can also go for web scraping to extract contemporary information from websites using automated web scraping tools. If you have enough budget opt for high quality data from Data marketplaces that allow you to purchase the specific type of data as per your model requirements. For large scale AI projects with a sufficient budget consider the service of an AI data services provider that delivers meticulously prepared data for your training needs.
In the quest for the right data, never compromise on privacy, security, and legal compliance. This might even lead you to data synthesis as for certain industries dealing in sensitive personal information like healthcare and finance it might get legally challenging to acquire the right kind of data abiding by the compliance regulations.
Data Synthesis
If data privacy laws are on your way to data sourcing, data available to train your ML model is insufficient, or you are looking for a faster turnaround time for collecting relevant and high-quality data then data synthesis can be a great alternative. Synthetic data can be generated based on statistical distribution or with the help of VAE (Variable Auto Encoders), GAN (Generative Adversarial Network), and synthetic data generation tools. Generative AI solutions today, provide tremendous support in generating synthetic data such as text, images, video clips, sound clips, and other content modalities.
Engineering and Preparing Your Data
Once you have the data it is crucial to define its quality and pass only high-quality and relevant data to your model for the desired outcome. This can be achieved through a couple of steps.
Data Exploration
Exploration is the first step in data preparation. Exploration helps to closely understand the relationship between datasets and speculate and refine future analytics questions and problems. Data exploration can be broadly broken down into three steps –
- Understanding what each variable represents from the data catalogs, field descriptions, and metadata.
- Detecting anomalies, outliers, and missing or incomplete data.
- Understanding the patterns and relationships among variables by plotting a dataset in various ways.
Data Cleansing
Data cleansing, often referred to as data cleaning or data scrubbing is the next step of data preparation. Cleansing helps to detect and correct invalid or missing data, bring consistency in format, and identify and remove duplicate records, data outliers, or out-of-date data. Data cleansing stages involve data quality assessment and audit, cleaning, verification of cleanliness, and validating the quality of the refined data.
Feature Engineering: Data Normalizing, Standardizing, Scaling
Data preprocessing is the unsung hero of successful AI/ML models. Data preprocessing involves feature engineering where the data is scaled to a uniform range. ML model training starts with the assumption that all features contribute equally. However, if the training datasets entered largely vary in range then ML algorithms tend to pay more weightage to higher values leading to a biased result. Normalization and Standardizations are feature scaling techniques that ensure uniformity of the numerical magnitudes of features by standardizing them all into a range between 0-1 following the Min-Max scaling or Z-score normalization thus preventing the domination of features with larger values in the results.
Once your data is ready to be fed as training data it is time to build your AI or ML model.
Building Your Models
The ability to build a high-quality AI model that serves as an asset for your business is governed by a set of factors. Model selection, training, and evaluation help in building the best-fitting model.
Model Selection
Among plenty of models available your enterprise should select the model and algorithms that offer the best outcome for a specific task or dataset while balancing the complexity and performance. Model selection techniques follow probabilistic measures like random train/test split, cross validation, bootstrap or resampling methods like, AIC (Akaike Information Criterion) to estimate the performance of a model. Your ultimate objective is to construct a model that fits the training dataset as well as is generalizable with unknown data. To filter this, you should perform a series of model training and comparison of evaluation metrics.
Tuning
Before training, many models require that certain hyperparameters, such as the learning rate, regularization strength, or the number of layers that are hidden in a neural network, be configured. Use methods like grid search, random search, and Bayesian optimization to identify these hyperparameters’ ideal values.
Training and Evaluation
Model evaluation is done with the objective of generalizability or the ability of a model to perform well on an unseen dataset. Each candidate is trained using a subset of the training dataset and then its performance is evaluated on the validation dataset. Model evaluation involves accounting for metrics such as accuracy, precision, recall, F1-score, and AUC-ROC.
Releasing and Optimizing Your Model
AI solutions should always keep themselves updated based on the currently available data in the market. The last thing that your customer expects is an irrelevant answer or failure to answer due to outdated data, as evident sometimes in the case of ChatGPT trained with data till April 2023. To keep a model in production relevant it should be registered, continuously monitored, and retrained to keep it upgraded.
Registration
Registering a model is a crucial MLOps practice where model files are stored in a repository called model registry for streamlining model development, evaluation, and deployment across your organization. To be able to continuously monitor your model in production and set up a model CI/CD workflow model registration is your first step. You can register your model in the AWS (Amazon SageMaker Model Registry) or Azure Workspace with the help of tools like Amazon SageMaker Pipeline, Azure Machine Learning Studio UI, or Python Azure Machine Learning V2 SDK.
Deployment
Before deploying a model you need to determine the frequency of results you are expecting from the model. Based on this deployment can be of two types, batch inference where results are not needed immediately, or real-time or online inference where results are required in real-time. The portability and scalability of your model are other factors that influence deployment decisions. For large or multiple models at scale plan for automatic training, testing, and deployment of models.
Monitoring
AI/ML models tend to degrade over time. Continuous monitoring detects potential issues such as model drift and training-serving skew. Design a data flow to handle training and prediction data. This may involve setting up an automated workflow leveraging ETL or utilization of orchestration tools to seamlessly feed data into the monitoring tool. Check if it is possible to acquire ground truth labels in the output data else monitor for prediction drift to see how far the distribution in predictions has shot up suddenly. Build dashboards with tools like Prometheus or Grafana to monitor your model.
Retraining
Retraining is a part of MLOps where the model is updated by training with new data. This is a very important task to keep your model always up-to-date and free from concept drift or data drift. Retraining can be periodic where a model is trained at a specific time interval. Alternatively, the model may be triggered for retraining upon failure to meet the performance threshold.
Model Constraints that Influence Your AI Solution
Apart from the technicalities, certain other constraints influence AI/ML model development.
Legal
Legal considerations are paramount when developing AI solutions. Organizations must comply with various data protection laws, such as the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States. These regulations dictate how personal data can be collected, processed, and stored. Failure to comply with these regulations can lead to significant fines and legal repercussions.
Ethical/Transparency
Ethical considerations are increasingly influencing the development of AI solutions. Organizations are expected to ensure that their AI systems operate transparently and fairly. This includes providing clear explanations of how algorithms make decisions and ensuring that these processes do not lead to discriminatory outcomes. Transparency is vital for building trust with users and stakeholders. Companies must also consider the ethical implications of their AI applications, such as the potential for misuse or unintended consequences. Establishing ethical guidelines and frameworks can help organizations navigate these challenges while fostering responsible AI development.
Historical (bias)
Historical bias in data is a significant concern for AI practitioners. Many AI models are trained on historical datasets that may reflect societal biases, leading to skewed outcomes when deployed in real-world applications. Organizations must actively work to identify and mitigate gender and demographic bias in their training datasets through techniques like data augmentation, bias audits, and diverse data sourcing. Addressing historical bias is not only essential for fairness but also for compliance with emerging regulations focused on equity in AI.
Security
Security is a critical aspect of any AI solution. Organizations must protect their AI models from various threats, including data breaches and adversarial attacks that could manipulate model outputs. Ensuring the security of both training data and deployed models is essential to maintain user trust and compliance with legal standards. Implementing robust security measures such as encryption, access controls, and regular security audits can help safeguard against potential vulnerabilities. Additionally, organizations should consider the implications of using third-party data or services in their AI solutions, as these can introduce additional security risks.
Conclusion
As evident from the above article data science forms the core of an AI development initiative. To start developing an Enterprise AI solution you must be able to take control of your data to maintain high-quality, bias-free data and consistent data supply for your AI/ML models. As a data owner, you should also be completely aware of ownership, accountability, and compliance with data privacy regulations (e.g., GDPR, HIPAA). Ensure responsible use of data and transparent decision-making processes in AI applications.

