Serverless architecture is where the application code is written separately without worrying too much about the server infrastructure. Adopting serverless is a move towards developing purely cloud-native codes functioning at the network edge. The application is broken down as small functions and this is why it is also called as function as a service (FaaS). The serverless code is event driven and may be triggered by a traditional HTTP web request or an incoming email.
The FaaS Functioning
In a FaaS model the product engineering team breaks down the application into small codes called function. Each function will execute a specific task when triggered by an event, like receiving an incoming email or processing an uploaded image. After going through a proper QA process the functions along with their triggers are containerized and uploaded to a cloud platform often with the help of some container orchestration tools like Kubernetes or AWS Fargate. It is the responsibility of the cloud provider to plan whether the functions perform from a running server or spin up a new one when triggered. Developers are abstracted from this infrastructure handling and cloud providers take care of providing the infrastructure as required.
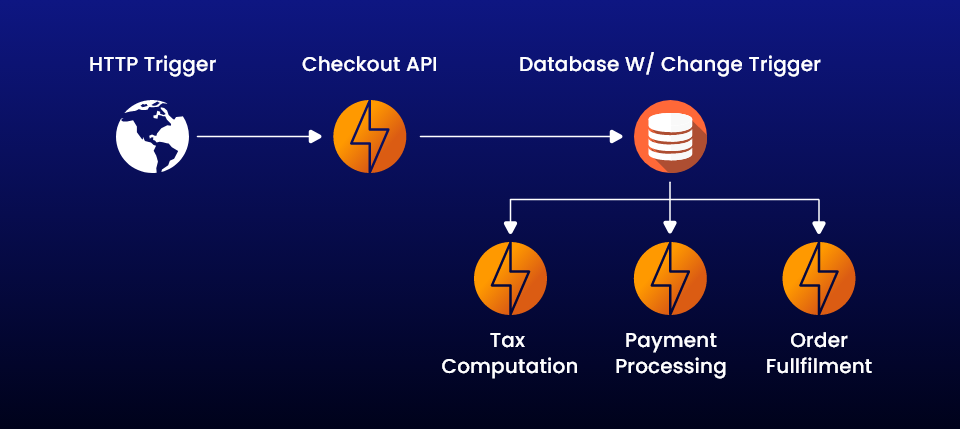
Considerations before Adopting Serverless Architecture
Managing state
Serverless functions are stateless. If business processes requires state then some separate solution can be used to provide state. However, adding state can hamper scalability so careful considerations should be made if the function absolutely requires state. Some of the popular solutions that provide state without compromising the benefits of serverless include:
- Using a temporary data store or distributed cache, like Amazon Elasticache on Redis.
- Store state in a SQL or DynamoDB database.
- Handle state through workflow engine like Durable Functions.
Long running process
Most cloud provider limit the runtime of a function to a maximum of around 10 minutes. Processes running longer than that needs to be managed. One solution is to break a process into smaller components that require lesser runtime. If the runtime of a process is longer due to some dependencies the process can be put through an asynchronous workflow.
Database updates and migration
The two best features of serverless is that they own their data and can easily release new functions without redeploying the entire application. However, legacy systems in reality feature a large backend database that must be integrated with the serverless architecture. If a relational database is involved it becomes difficult to update schema. A popular way to update schema is by never modifying existing properties and columns but add a new field as required to run the new serverless function.
The Advantages of Serverless
High density
Many instances of the same serverless code can run on the same host compared to containers or virtual machines. The instances scale across multiple hosts addressing scale out and resiliency.
Micro-billing
Most serverless providers bill based on serverless executions, enabling massive cost savings in certain scenarios.
Instant scale
Serverless can scale to match workloads automatically and quickly.
Faster time to market
Developers focus on code and deploy directly to the serverless platform. Components can be released independent of each other.
Business Use Cases of Serverless Architecture
Full Serverless Backend
Full serverless backend is suitable for building new applications or applications based on microservices architecture and heavily reliant on APIs. Some examples of such applications are:
- API-based SaaS products (example: marketplace application).
- Message-driven applications (example: patient monitoring solution).
- Apps focused on integration between services (example: train booking application).
- Processes that run periodically (example: timer-based database clean-up).
- Apps focused on data transformation (example: import triggered by file upload)
- Extract Transform and Load (ETL) processes.
Monoliths
Migrating monoliths to cloud is a challenging task and “lift and shift” is the preferable approach. In one approach initially the entire codebase is lifted and migrated to the cloud . Then, some of the services are refactored and modernized as functions and the client is redirected to use them instead of the original one. The combination of a serverless architecture and proxies helps to integrate microservices and their own databases to the cloud successfully. The monolith code gets redundant and starved (its services no longer called) until all its functionalities are replaced.
Mobile back ends
The event driven nature of serverless architecture makes it ideal for building mobile applications. The backend is completely abstracted from the developer. The developer can build the frontend without requiring any knowledge of the backend in his preferred language. The serverless nature also enables sharing endpoints between various teams and allows them to work in parallel. The freedom from not worrying about the backend platform architecture and its programming paradigms allows developers to focus on core business logic.
Internet of Things (IoT)
The IoT consists of several devices connected with each other exchanging information or sharing to a central cloud database on some defined triggers. The event driven nature of serverless architecture makes it ideal for handling such a user scenario. The serverless nature allows for fast scaling as devices and volume of data increases. The IoT ecosystem also demands integration of new endpoints to support new devices and sensors which is again perfectly served by a serverless setup. Also the system is secure from versioning glitches as updating business logic for a particular device doesn’t demand re-deployment of the entire system.
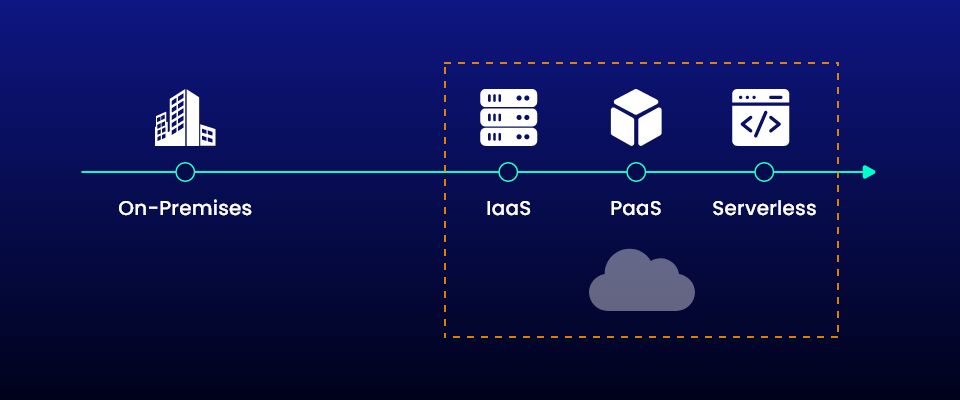
Comparison Between Serverless Architecture and PaaS
Serverless and Platform-as-a-Service (PaaS) are somewhat similar in nature as they both isolate the backend from developers however there are some interesting differences in terms of scalability, pricing, startup time, and the ability to deploy at the network edge.
Serverless application scales automatically and instantly on triggers but application in PaaS takes some time to spin up. The start up time for serverless is relatively low when compared to PaaS due to its ability to instantly scale on trigger. On-demand scaling is not an intrinsic feature of PaaS, and developers need a certain amount of forecasting for proper scaling.
As an advantage of high scalability serverless can scale down to shutting down functions when not required to no activity and then swiftly scale up. This allows a precise pay-as-you-go model of billing for serverless operations. On the other hand the PaaS model which can’t calculate the usage so accurately tends to be a bit higher on the billing side. Serverless vendors charge only for the precise amount of time a function is running while PaaS vendors charge for the applications used or a flat monthly fee. To prevent latency in user experience, at least some functions of PaaS applications need constant running.
Conclusion
Serverless architecture is a step ahead towards building completely cloud-native applications due to its high backend abstraction objective. However, careful considerations should be made by the developer team before embarking on a migration to the serverless computing environment whether it suits the nature of application architecture. Several big players like AWS, Microsoft Azure provide the necessary infrastructure and tooling support for migrating to a serverless platform. The credit lies on proper feasibility and technology audit to correctly assess the service abstractions and information architecture and expert cloud consultation to help in choosing a serverless cloud provider.

