We help organizations to prepare their data for analytics, AI, and ML to derive value from them. Data today comes in various formats that need to be normalized, cleansed, integrated with traditional sources (often existing data warehouses), and then enriched. Transformed data provides a faster, easier way to perform data and analytics engineering and, as a result, delivers greater control over your data.

Gleecus TechLabs Inc. provides data transformation solution to all organizations at the different stages of Data Engineering to extract, clean, convert, and structure data into consumable format for analytics and data mining.
We help you to assess your data collection, storage, analysis, and delivery methods to build a data strategy conforming to your unique business needs.
Bring in the devlopment, operations, and engineering team together under a common data platform to avoid data silos.
We build streamlined pipelines for automatic extraction, transformation, and loading of data into suitable data warehouses and data lakes ready for analytics consumption.
Leverage powerful AWS services like AWS Glue or AWS Data Pipeline to process and transform raw data to high quality, accurate data ready for complex analysis.
From Data Lakes to Data Analytics tools we leverage the power of Azure Data Engineering solutions to formulate a robust data architecture for driving actionable insights from your data.
Execute data ingestion, data management, ETL processes and implement data governance on the robust Data Lakehouse platform.
At the beginning we conduct workshops and discovery calls to get a high-level overview of your business, problems faced, and review of your business’s dataset.
At this stage we get in touch with your technical team to identify various data sources from where structured and unstructured data can be collected. We determine the relevancy of these different sources for your project and prioritize them.
At this stage we deploy a data lake to collect and store unstructured data from various sources identified by our data engineering team ready for further processing and analysis. Establishing a data storage strategy is foundational for a successful data engineering project.
Once the data lake is ready it is time to establish a data ingestion process. Orchestrator tools are utilized to automate the data flow. Advance data pipelines to extract, clean, and load data are built leveraging ETL/ELT techniques. This stage involves converting data into a homogeneous structured format for consumption by various BI tools and AI/ML engines.
This is the final stage where data is visualized to deliver meaningful interpretation for business analysts leveraging BI tools. This stage also uses natural language tools to query processed data.
Connect, validate, query, and visualize your enterprise data with intuitive, natural language commands. No coding required.
Let AI be your BI Team.
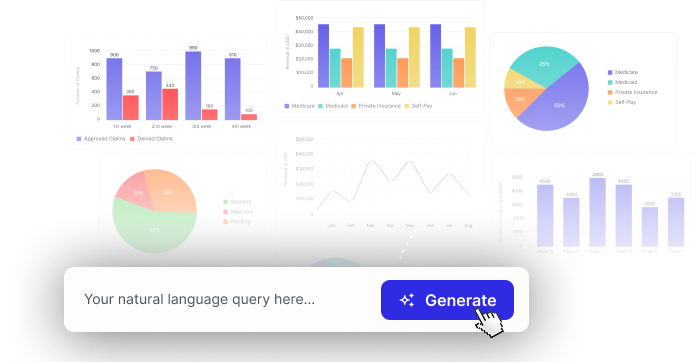
Moved the on-prem data of a leading healthcare revenue company to the cloud without interrupting their BI dashboards. The entire project was conducted keeping in mind a limited timeline and budget leveraging our team’s expertise and data engineering solutions like Data Factory, Data Bricks, and ADLS.
A cloud first enterprise platform wanted to enable its customers to take business-critical decisions in real time based on data spread across different platforms. Built a data ingestion feature BYOD (Bring Your Own Data) to ensure access to uniform data across customer products.
























We seamlessly integrate with a variety of ecosystem partners and platforms to enable greater flexibility and speed to market.



We believe in partnering with organizations to help them discover the power of technology by unlocking their true digital potential.