Over the past few years, cloud migration has seen extensive global adoption, but the recent trend to remote working has caused businesses to rely more than ever on cloud services and apps.
However, the advantages of a thorough and effective digital transformation cannot be completely realized without careful planning and research of your business needs and existing data. The digitization of processes, non-unified data stores, and multiple systems of record keeping over the years might require revamping the organization’s whole operating model.
What Are the Driving Factors for Cloud Adoption
Spend Less and Get More

With a pay-as-per-you-go model adopting cloud technology for data handling and management seems very cost-effective. Businesses will spend lesser on expensive hardware purchases and maintenance, as well as on IT. The IT team is free to work on other crucial tasks because the cloud provider handles upgrades and maintenance.
Get Data Insights

With the advanced analytic capabilities of the cloud, business data can be studied to make valuable business insights, set new goals, and develop strategies.
See Productivity At All Levels

The remote access feature of a cloud allows employees of an organization access files and documents from anywhere across the world increasing productivity. The IT staff may concentrate on innovation and company advancement rather than the ongoing tasks of updating software and licencing, handling security breaches, and maintaining equipment.
Cloud optimize hardware usage through virtual machines leading to better hardware performance, cost savings, and increased productivity. Additionally, the cloud ensures data redundancy as it keeps your data intact even if you lose access to a particular machine or a data center goes offline.
Some of the Challenges to Cloud Adoption Faced by Large Organizations
Lack of data interoperability in legacy systems

Organizations don’t want to be bound to one cloud provider but have the flexibility to move applications from one cloud to another as per their requirement. This flexibility brings up some challenges like:
- Rebuilding the application and application stack in the target cloud.
- Seamless integration of network support between the source and target cloud.
- Secure handling of data in transit and decryption at the target cloud.
Increased budget to build new architecture

Sometimes organizations prefer refactoring the migration and changing the architecture of applications. This can save cost and make the applications adaptive to a new environment.
However, what can influence refactoring is the skills required for such an execution. This can cost time or altogether the integration may go wrong due to an error in code at the configuration or integration level.
Fear of data security in public cloud

Many organizations have this ominous feeling that data is not safe in shared public clouds, though it is not true. Some also don’t want to lose control over data management by shifting to a public cloud infrastructure as in the case of IaaS (Infrastructure As A Service) Architecture.
This mandates them to maintain their own data store. However, the in-house IT team might not be skilled enough to change the architecture of the internal application to match with that of the Cloud provider.
Problems with traditional API architecture
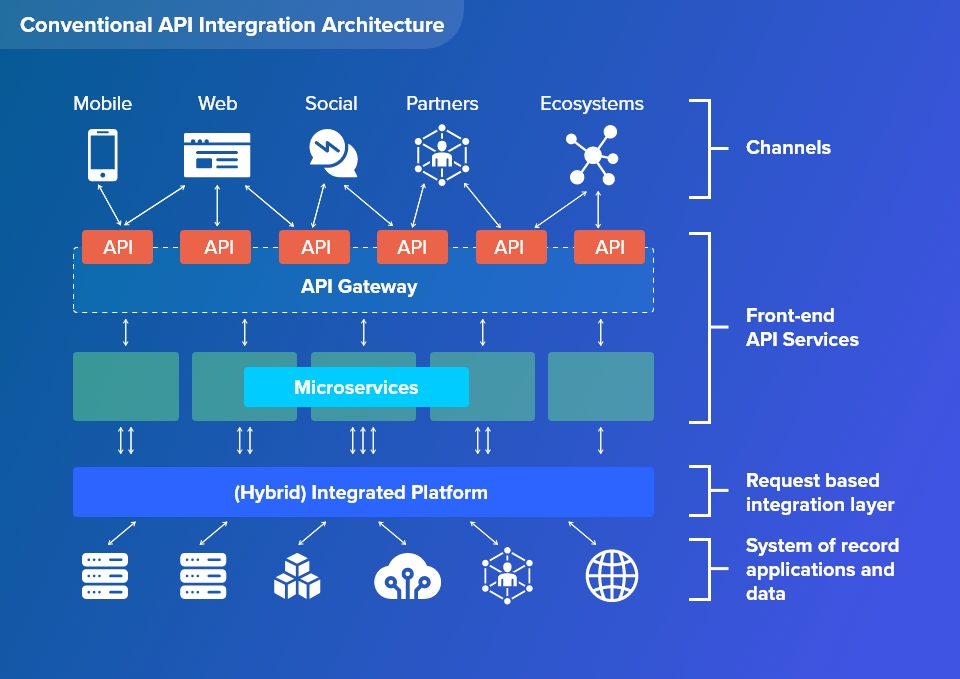
Traditional API architecture can lead to latency, downtime and create dependencies for non-cloud app. Backend systems bear the load of responding to API requests.
Unlike third party cloud service provider the data returned by the backed system is typically bound to the data structures of the backend system. This could lead latency issue if proper data management system is not in place.
To overcome the challenges of traditional architecture organizations might adopt a DIH through a High Performance Data Store and for seamless integration of service applications and data stores to cloud.
What is a Digital Integration Hub?
A digital integration hub is an IT architecture that separates digital applications from legacy backend record systems. A DIH collects data sets spread over multiple backend record system and stores into a low latency, scale-out data store.
Organizations are worried about data privacy and may prefer to continue using their on-premise operating systems instead of using public cloud. DIH supports smooth cloud migration through a decoupled API layer for integration of backend data storage system to a hybrid cloud. The DIH architecture consists of a HPDS (High Performance Data Store) sitting between the integration and service layer.
DIH removes unnecessary complexities and the cost involved with maintaining multiple backend record system. It also helps in generating real-time operational reporting of new data through its data analytics features.
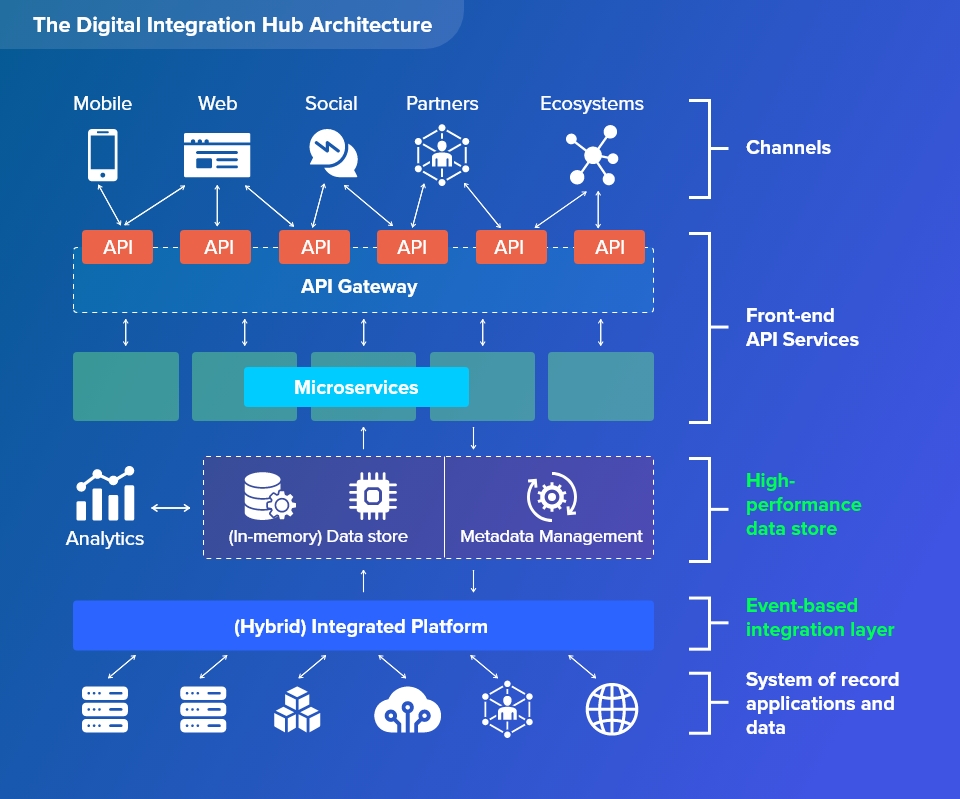
The Role of High-Performance Data Stores
A High-Performance Data Store, also known as in-memory data store, is a collection of networked, clustered computers that pool their random-access memory to enable data exchange between clustered applications (RAM). The DIH architecture must have a High-Performance Data Store to keep up with the exponential rate of data growth.
High-Performance-Data-Stores aids secure storage and management of both structured and unstructured data. It is a secure method for conserving data sets that expand over time, ensuring that the data is constantly accessible upon request.
They do millions of input and output operations per second (IOPS) while processing complicated data in heavy workloads, ensuring that the data is always available on demand. Due to its quick ability to spot patterns, correlations, and anomalies in large data sets, the high-performance data store greatly accelerates search times for unstructured data.
The high-performance data store employs a multi-tiered storage method to hold different types of data to enhance overall user experience for mission-critical applications. To optimize data storage, it distributes the various data types among different storage medium (tiers), as determined by performance, availability, and costs.
The in-memory tier consists of solid-state-drives (SSDs) and stores the most critical data. Less critical data are stored in hard disk drives (HDDs) in a separate tier. Sometimes there might be a third type of tier for data archiving in the cloud.
Tiered storage allows applications to run hybrid queries (operational and analytical) on the records stored in any tier without sacrificing performance, which reduces the cost of ownership.
Advantages of HPDS
- APIs needn’t compete with core processing functions of the SoR and can deliver a quicker user response.
- SoRs don’t get overloaded with API requests.
- Decoupling of the API from SoRs allows 24×7 availability and prevents the consumer from the pain of replacing legacy system.
- Heavy lifting, normalizing, aggregating of data and running analytics and generating reports can be tasked with HPDS relieving the SoRs.
Why is a DIH Useful?
Organizations undergoing digital transformation must integrate their core business systems with hybrid cloud deployments in a flexible, timely, and effective manner. In this case, the in-memory DIH is useful, especially when the core business system in mission-critical business operations is frequently a mainframe.
High volumes of crucial data produced by mission-critical business systems must be synchronized with cloud applications. Due to their tight coupling, conventional architecture don’t support modernization, which makes it harder to update each record system because you also need to update the digital applications that access them.
We do not have to be concerned about data synchronization across the application, cache, and record systems while using a DIH. Using modern protocols, we may quickly access all crucial data in a central, high-performance data management layer. The DIH boosts throughput, lowers latency, and ensures continuous application availability by decoupling API services from record systems.
Real World Use Cases
Organizations employ DIH for a variety of applications due to its performance and flexibility.
Sensor Data Integration

Many firms today use sensors to collect data. Integrating this data with information from other sources is a challenging task. Real-time processes are driven by sensor data and require repeated API requests. A DIH facilitates effective data caching for fast delivery.
Technology Scaling

Businesses that manage petabytes of data can scale more quickly without performance degradation with the aid of a DIH.
Big Data Management

A DIH improves big data management efficiency by enabling data integration and analytics. Additionally, it offers real-time reporting of new data in business processes.
API Call Management

DIH is used for API call management and call reduction. Enterprise applications can access data from multiple databases for the shared data access layers created by the DIH. Real-time analytics spanning operational and historical data are applied by DIH.
Examples patterns of integration layer
The integration layer should accommodate a variety of patterns, albeit these will change depending on the needs of the organization. Examples are
- Event brokering / messaging
- Extract Transform & Load (ETL)
- Change Data Capture (CDC)
- Integration Patterns (ESB, iPaaS)
- Stream processing (Spark, Flint)
Conclusion
Business in today’s world demands agility, quickness, and adaptability. While cloud computing offers all of the above, sometimes improper integration of two architectures may lead to unfavorable outcomes. The adoption of a DIH architecture ensures the complete decoupling of data systems with the application layer. Chances of latency, downtime and security breach are highly reduced.
